数据管理配置
概述
配置问数助理的数据分析来源,预置了部分开箱即用的钉钉一方应用数据,也支持企业上传自有数据,主要包括以下几种数据源类型:
本地表格:支持.xls、.xlsx、.csv格式文件。
钉钉多维表:支持分析钉钉多维表数据。
本地数据库:支持MySQL、Hologres等多种行业主流数据库。
钉钉数据资产平台:支持使用数据资产平台加工后的数据集。
钉钉官方应用数据:支持使用部分钉钉官方应用数据。
场景 1:基于本地表格的数据进行智能分析
功能使用效果
功能搭建流程
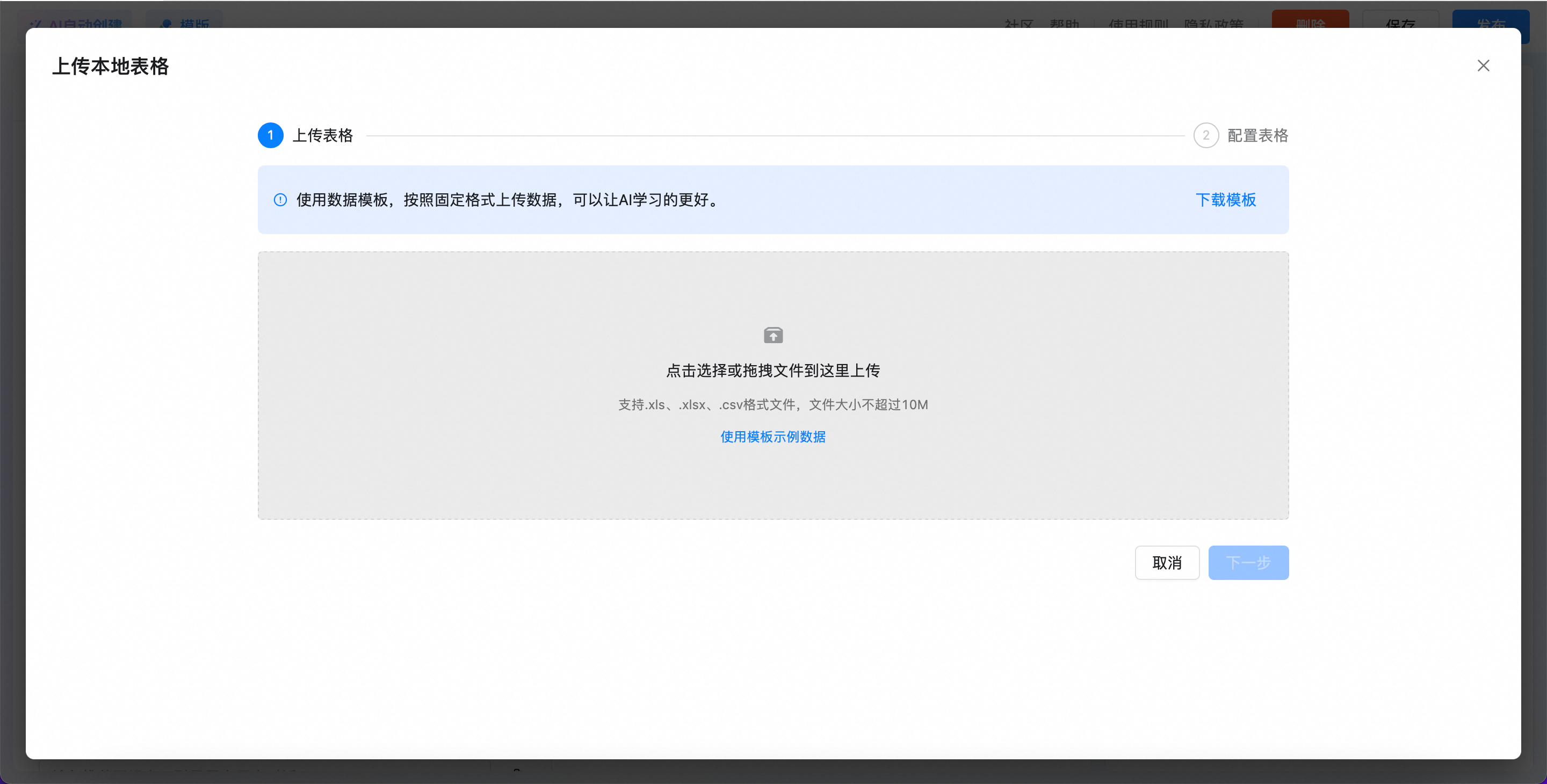
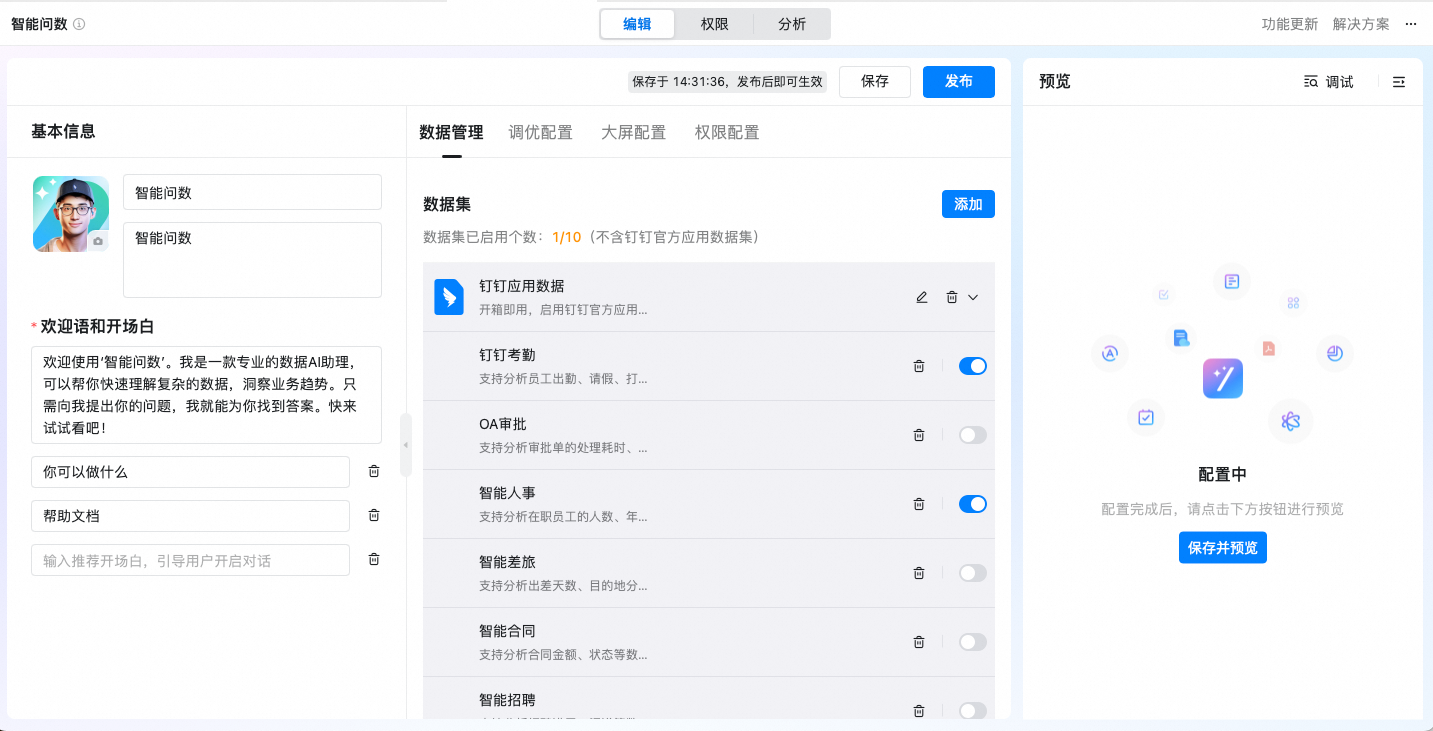
单击添加数据源,选择本地表格。
进入上传本地表格页面,你可以上传表格文件,目前支持的格式有
.xls、.xlsx、.csv,文件大小不能超过 10 M。说明初次使用时,可以单击“下载模板”,使用数据模板,按照固定格式上传数据,可以让AI学习的更好;或是单击“使用模板示例数据”,快速体验过程。
本地表格暂仅支持 1 个 sheet,最多仅支持 40 列。
本地表格的表头不能存在空值,字符长度最多不超过 30,表头不能重名,否则会影响大模型理解的准确度。
本地表格的内容不要包括合并单元格、图片等,否则会影响内容解析。
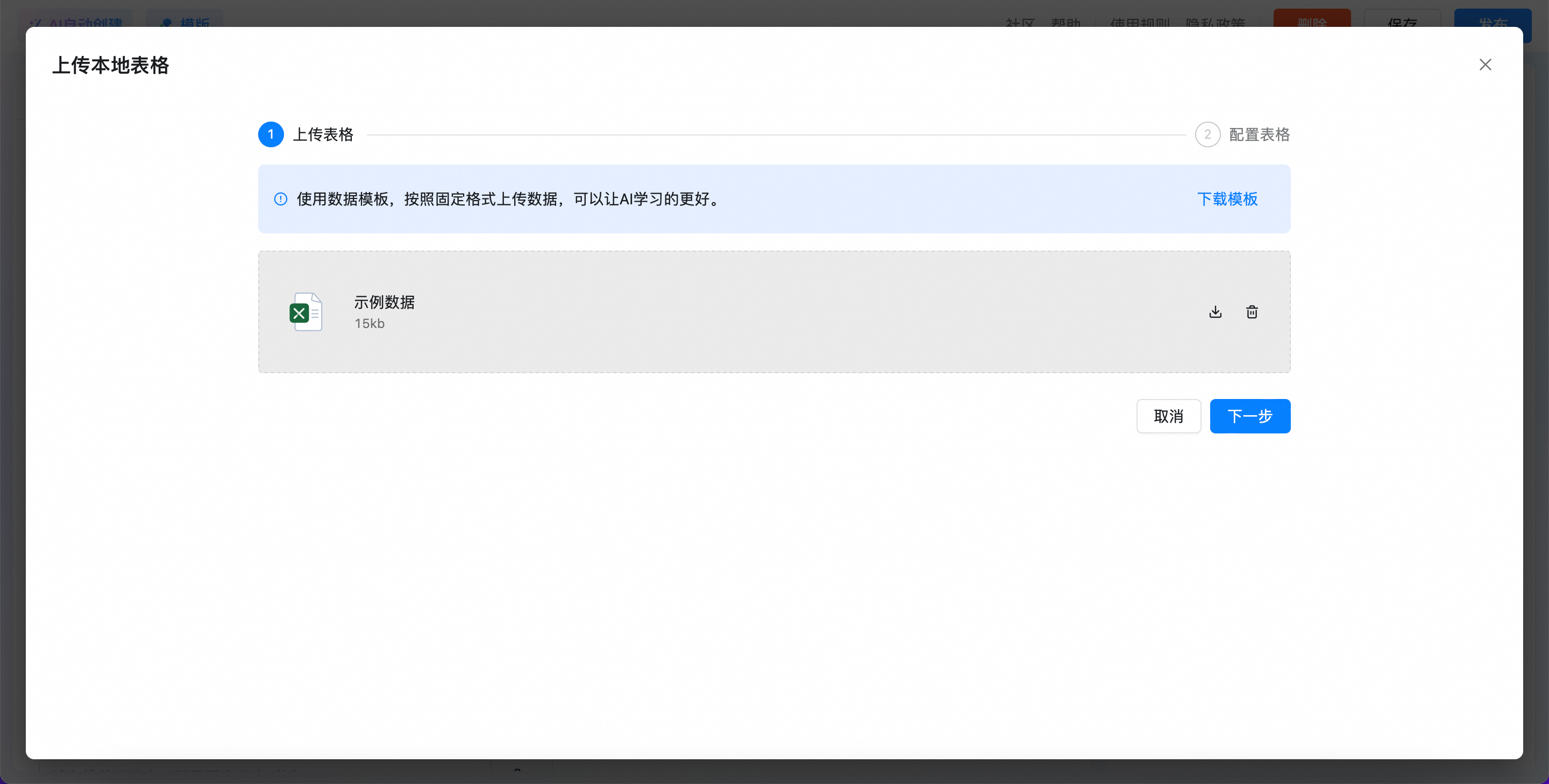
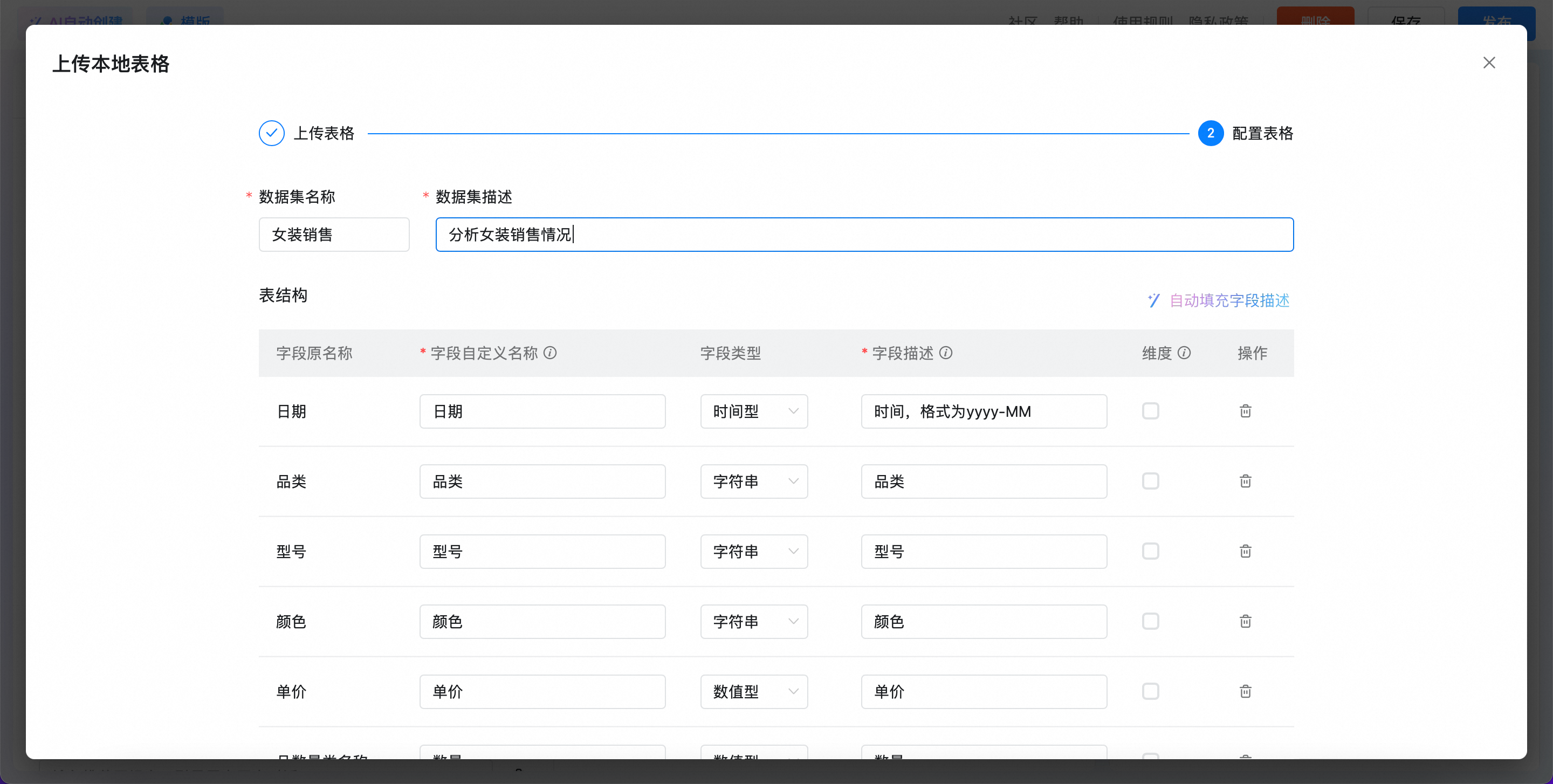
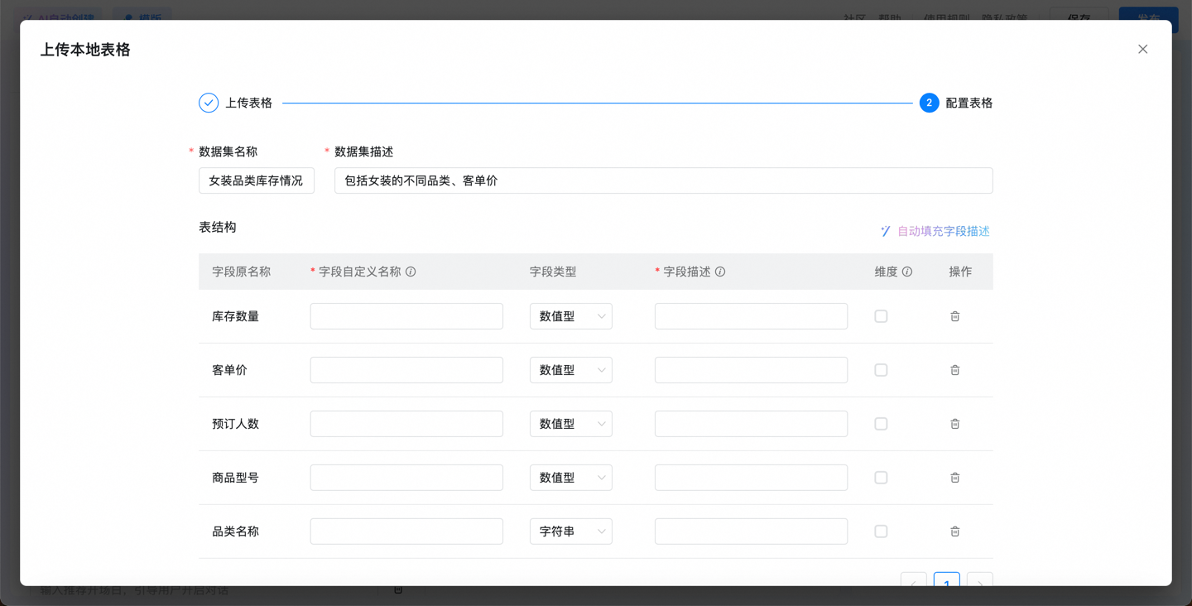
上传完成后,单击下一步,进入配置表格内容:
功能
具体说明
数据集名称
用于做数据集的区分
数据集描述
描述清楚数据集的分析场景和内容,当选择多个表时,用于帮助大模型进行表路由
表结构
字段原名称
系统自动解析本地表格的表头生成,不可修改
字段自定义名称
直观的中文名称,用于可视化展示的名称,简洁明确。例如,birth_date 的中文名为“出生日期”
字段类型
系统自动解析生成,支持修改,包括字符串、数值型、时间型
字段描述
详细描述字段用途和规则,帮助大模型更好的理解字段含义。例如 birth_date 的备注可能是“格式为YYYY-MM-DD,用于计算年龄”
维度
维度是指分析数据的视角,比如日期、商品品类、产品名称等,用于帮助AI根据用户提问进行优先匹配,维度列的字段类型一般是字符串
配置完成后,可以在数据管理列表通过开关来决定数据集是否生效。
场景 2:基于钉钉多维表的数据进行智能分析
功能搭建流程
单击添加数据源,选择多维表
进入选择多维表页面,你可以选择自己有查看权限的多维表,支持分析以下多维表的字段
多维表字段
值示例
文本
这是个文本
单选
保存key,服务端查询时转换
多选
保存key,逗号分隔,服务端查询时转换
人员
人名
群组
群名
部门
部门名
日期
格式yyyy-MM-dd
数字
整数转为long,小数转为double
复选框
字符串
附件
地址
链接
-
进度
数值
地理位置
地名
条码
-
电话
-
地址
-
评分
数值
货币
-
邮箱
-
身份证
-
手写签名
图片地址
自动编号
-
创建人
人名
更新人
人名
创建时间
格式yyyy-MM-dd
最后更新时间
格式yyyy-MM-dd
富文本
-
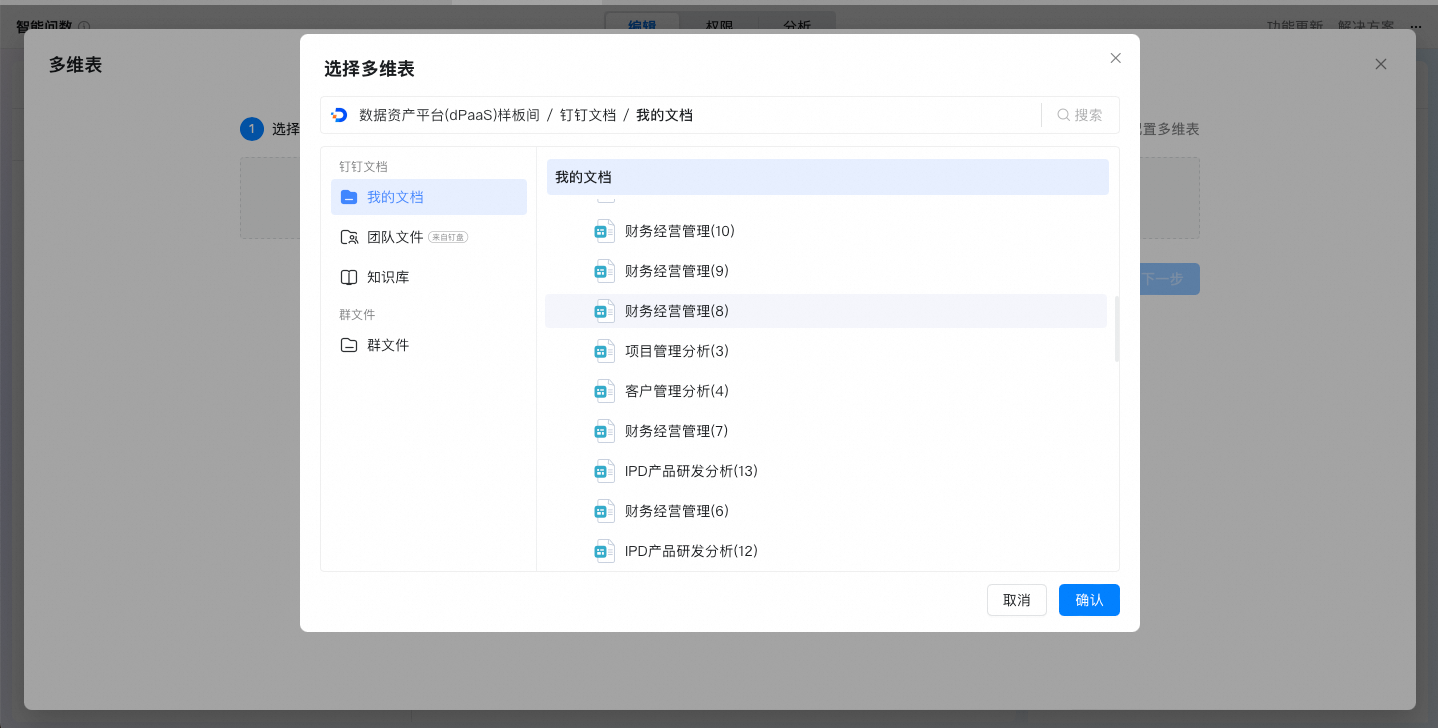
选择后,进入配置多维表内容:
说明多维表内容实时更新同步。
多维表的子表和表头更新时,需要手动单击刷新按钮更新。
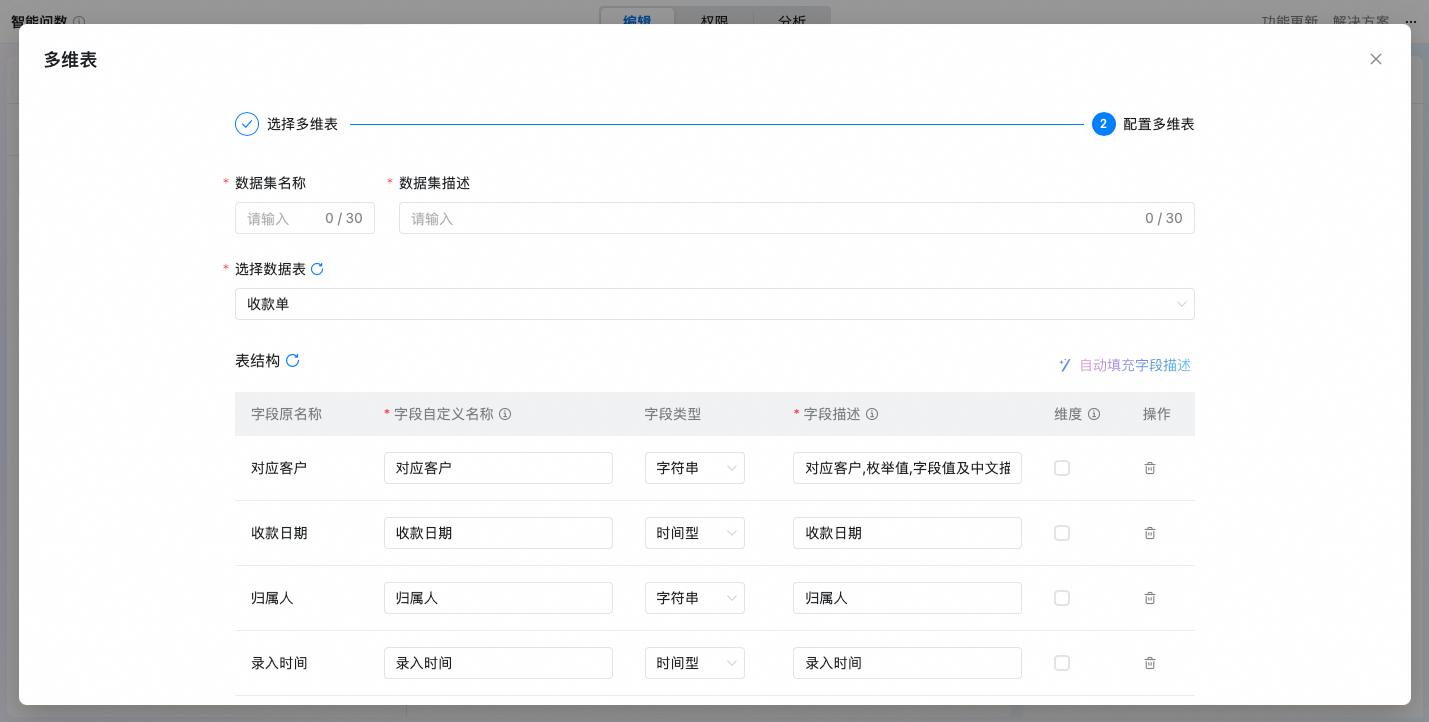
功能
具体说明
数据集名称
用于做数据集的区分
数据集描述
描述清楚数据集的分析场景和内容,当选择多个表时,用于帮助大模型进行表路由
表结构
字段原名称
系统自动解析本地表格的表头生成,不可修改
字段自定义名称
直观的中文名称,用于可视化展示的名称,简洁明确。例如,birth_date 的中文名为“出生日期”
字段类型
系统自动解析生成,支持修改,包括字符串、数值型、时间型
字段描述
详细描述字段用途和规则,帮助大模型更好的理解字段含义。例如 birth_date 的备注可能是“格式为YYYY-MM-DD,用于计算年龄”
维度
维度是指分析数据的视角,比如日期、商品品类、产品名称等,用于帮助AI根据用户提问进行优先匹配,维度列的字段类型一般是字符串
配置完成后,可以在数据管理列表通过开关来决定数据集是否生效。
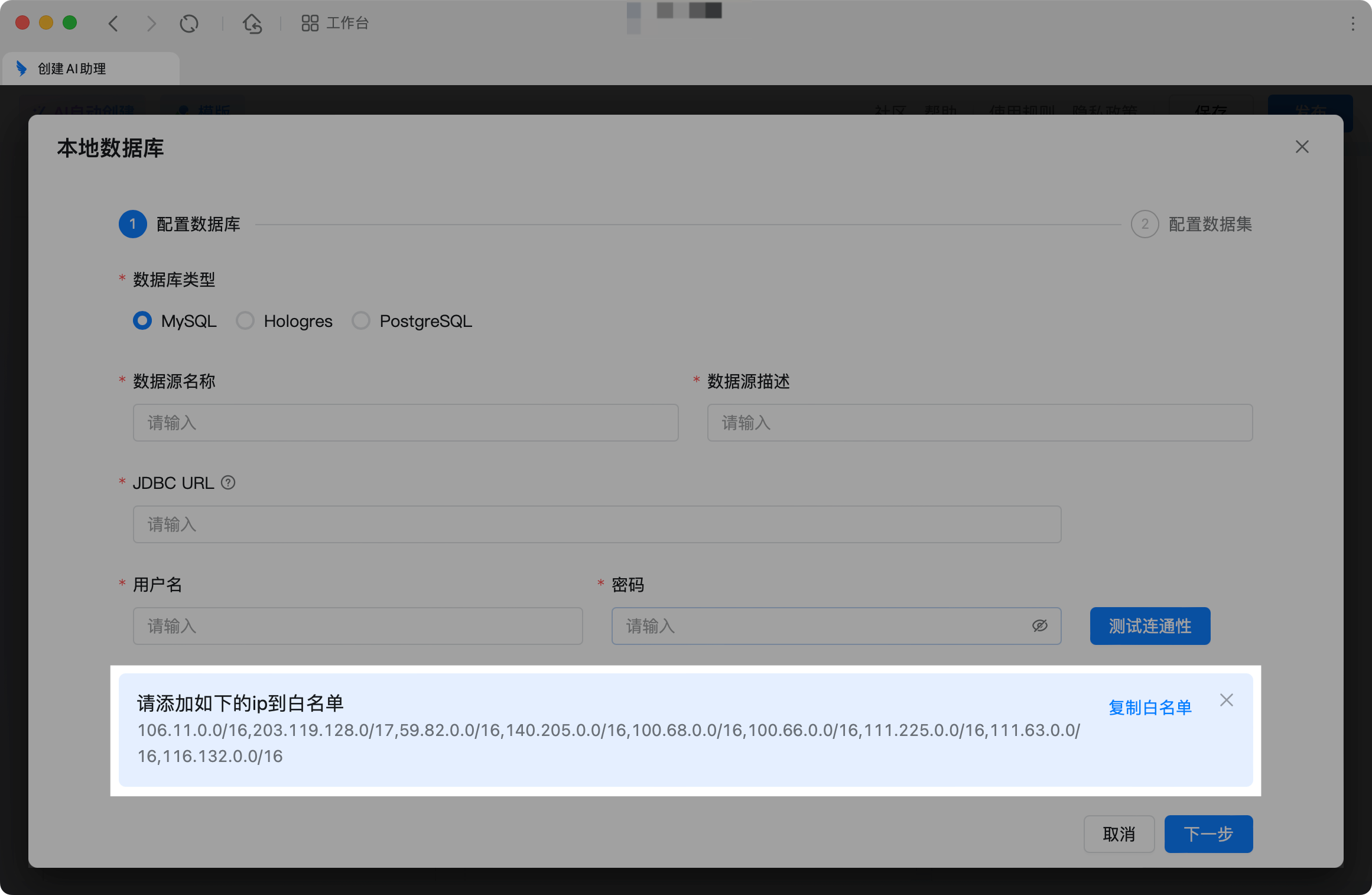
场景 3:基于本地数据库的数据进行智能分析
功能搭建流程
单击添加数据源,选择本地数据库。
进入本地数据库配置页面,配置内容如下。
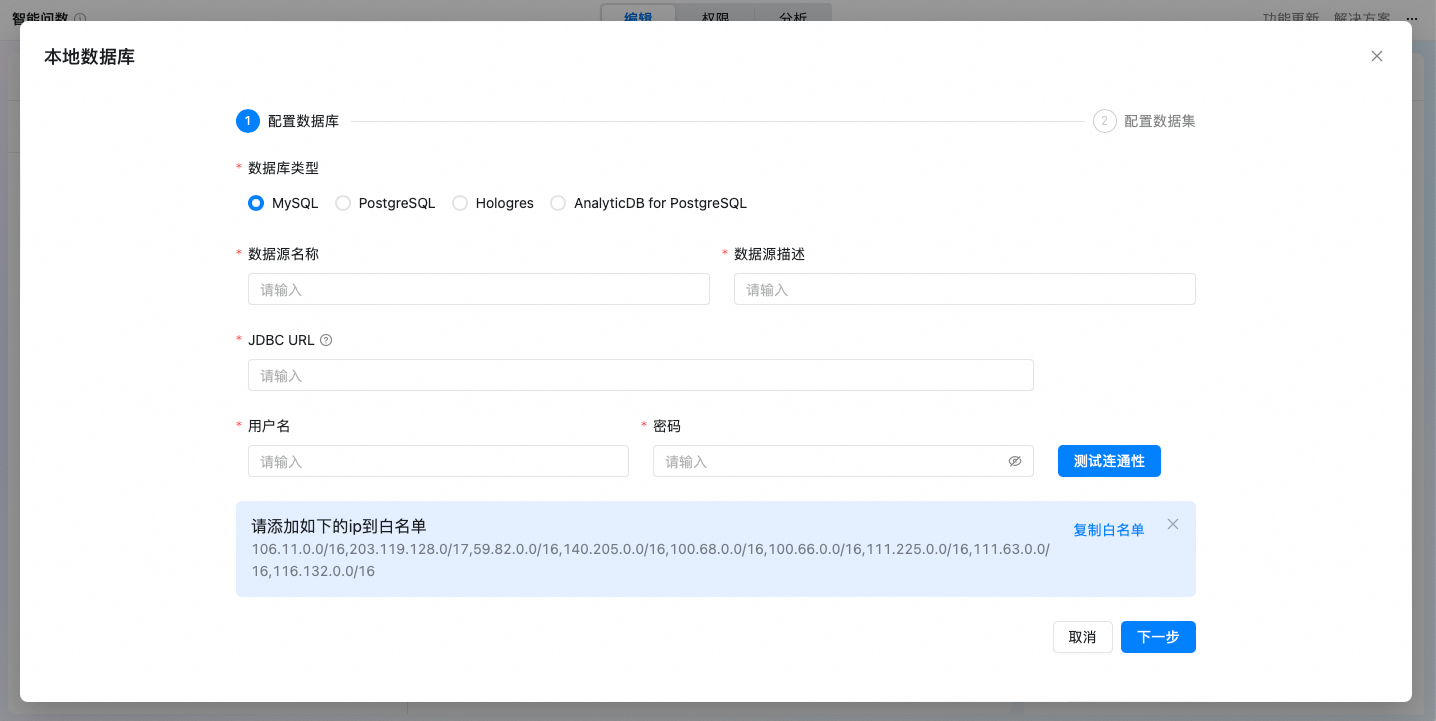
功能
具体说明
数据库类型
支持MySQL、Hologres、PostgreSQL、AnalyticDB for PostgreSQL、SQLserver(2016及以上)和 Oracle(12c及以上)
数据源名称
用于做数据源的区分
数据源描述
用于做数据源的区分
JDBC URL
示例:jdbc:<databaseType>://<server>:<port>/<databaseName>
用户名和密码
正确输入后请单击“测试连通性”,保证数据库联通成功,然后才能进行下一步
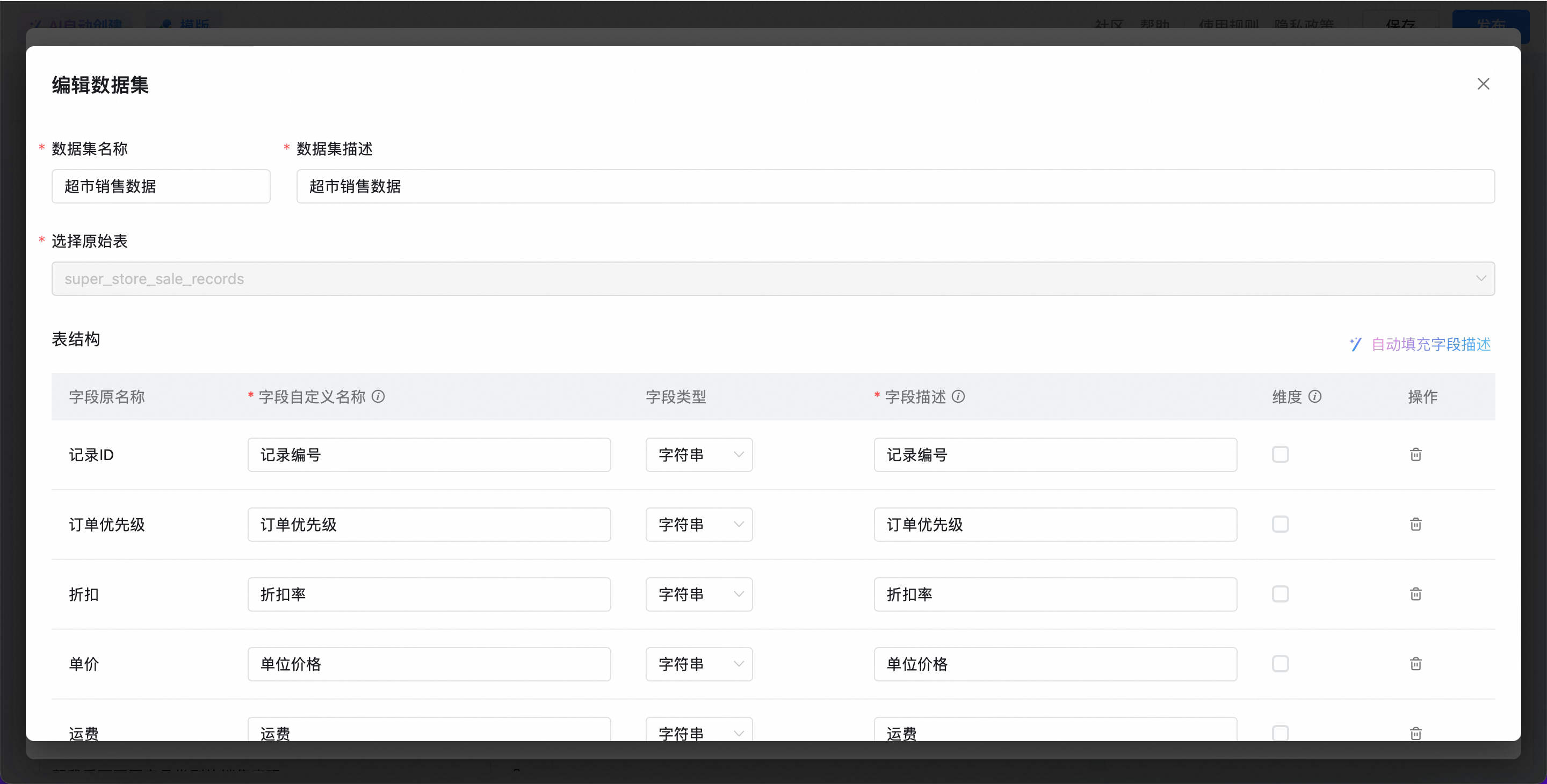
配置完成后,单击下一步,进入配置数据集页面,支持新建多个数据集,配置内容如下:
功能
具体说明
数据集名称
用于做数据集的区分
数据集描述
描述清楚数据集的分析场景和内容,当选择多个表时,用于帮助大模型进行表路由
选择原始表
选择数据库中的表,不可重复选择
表结构
字段原名称
系统自动解析数据库中的物理列名称,不可修改
字段自定义名称
直观的中文名称,用于可视化展示的名称,简洁明确。例如,birth_date 的中文名为“出生日期”
字段类型
系统自动解析生成,支持修改,包括字符串、数值型、时间型
字段描述
详细描述字段用途和规则,帮助大模型更好的理解字段含义。例如 birth_date 的备注可能是“格式为YYYY-MM-DD,用于计算年龄”
维度
维度是指分析数据的视角,比如日期、商品品类、产品名称等,用于帮助AI根据用户提问进行优先匹配,维度列的字段类型一般是字符串
说明原始表名也会用于模型推理,原始表名尽量用表意的全小写+下划线(如market_sales),避免使用中文物理表名,大小写、中文、特殊符号混用的表名,以及超长的表名
字段原名称代表数据库中原始的物理列,字段原名称的和原始表名类似,避免使用中文列名,大小写、中文、拼音、特殊符号混用的列名,列名尽量使用贴合业务含义的英文,单词间用下划线分割
不同表中代表同一含义的字段,尽量使用统一的值格式,比如日期,避免一部分字段使用的是日周月,一部分是月,一部分又是精确到天;又比如公司名,部门名,产品名等,尽量使用全称,避免使用简写或拼音
配置完成后,可以在数据管理列表通过开关来决定数据集是否生效。
场景 4:基于数据资产平台加工后的数据集进行智能分析
功能搭建流程
单击添加数据源,选择钉钉数据资产平台。
选择数据集,若要对原始数据进行清洗,融合、转换等处理请到数据资产平台,详见数据工厂。
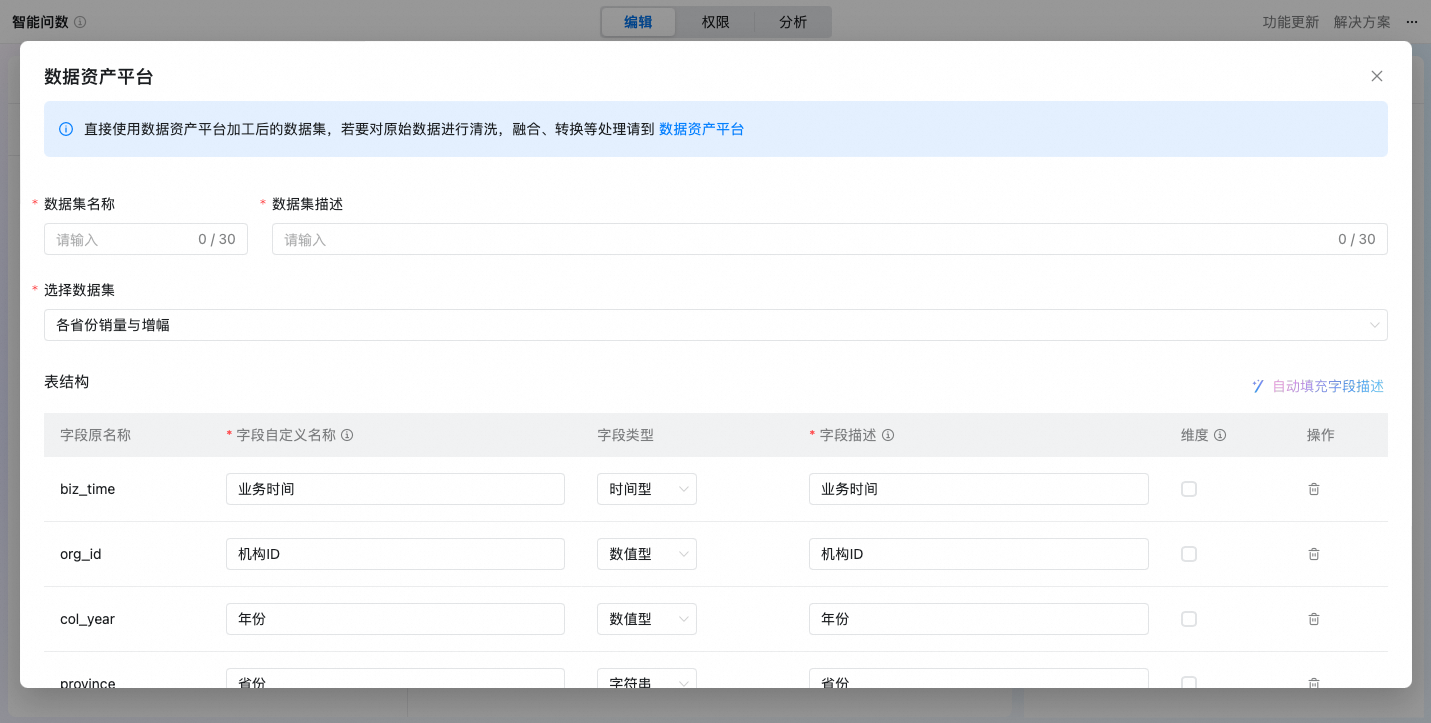
配置完成后,可以在数据管理列表通过开关来决定数据集是否生效。
场景 5:基于钉钉官方应用数据进行智能分析
功能使用效果
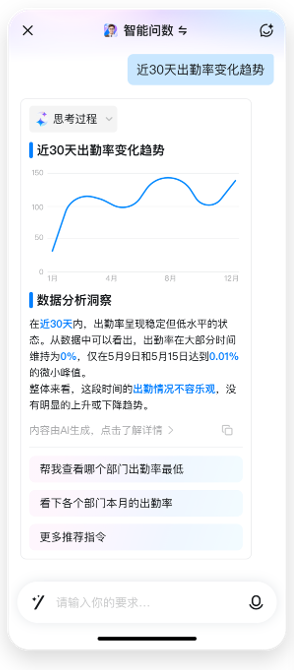
功能搭建流程
单击添加数据源,选择钉钉官方应用数据。
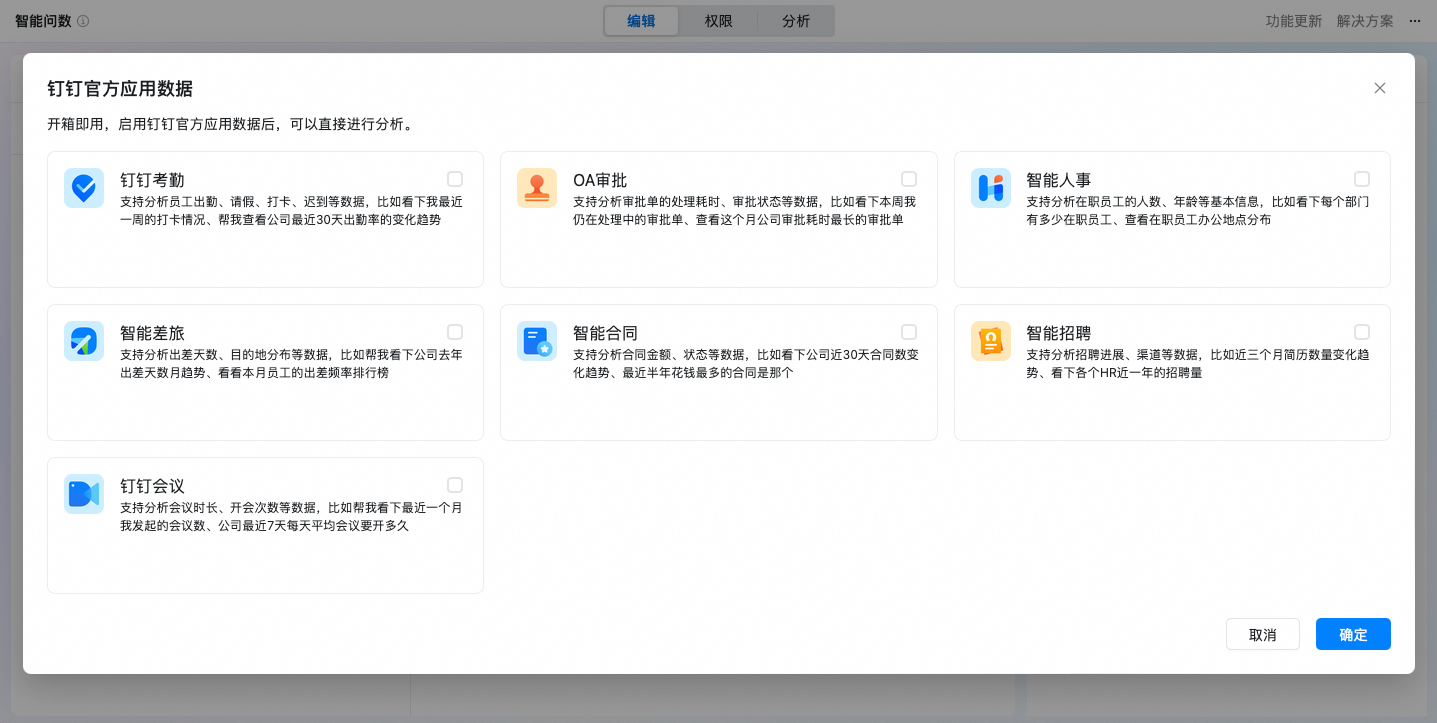
选择希望分析的官方应用场景,包括考勤、审批、人事、差旅、合同、招聘、会议(其他钉钉应用数据持续丰富中)。
钉钉应用数据
具体说明
钉钉考勤
支持分析员工出勤、请假、打卡、迟到等数据,比如看下我最近一周的打卡情况、帮我查看公司最近30天出勤率的变化趋势
OA审批
支持分析审批单的处理耗时、审批状态等数据,比如看下本周我仍在处理中的审批单、查看这个月公司审批耗时最长的审批单
智能人事
支持分析在职员工的人数、年龄等基本信息,比如看下每个部门有多少在职员工、查看在职员工办公地点分布
智能差旅
支持分析出差天数、目的地分布等数据,比如帮我看下公司去年出差天数月趋势、看看本月员工的出差频率排行榜
智能合同
支持分析合同金额、状态等数据,比如看下公司近30天合同数变化趋势、最近半年花钱最多的合同是那个
智能招聘
支持分析招聘进展、渠道等数据,比如近三个月简历数量变化趋势、看下各个HR近一年的招聘量
钉钉会议
支持分析会议时长、开会次数等数据,比如帮我看下最近一个月我发起的会议数、公司最近7天每天平均会议要开多久
配置完成后,可以在数据管理列表通过开关来决定数据集是否生效。
 说明
说明官方应用数据开箱即用,暂不支持手动调优。
数据预处理技巧
数据集配置
数据集的名称及描述贴合业务,最好是中文;
不同数据集的描述要有所区分,以帮助大模型进行表的路由;
数据集的字段名称及描述贴合业务,描述里面备注清楚业务含义(如同义词,业务含义等),最好把示例值也展示出来,比如名称“类目”描述“也可以叫类型、分类,值不同服装的类目,包括女装、男装、童装”;
同一数据集的不同字段的名称要有所区分,以帮助大模型更精准地选列,避免出现含义重叠,含义冲突的列(例如,某列名叫地区,实际的值却是省份)
维度列一般是值可枚举的字符串列,如地区、省份、名称等,勾选维度类可以帮助AI根据用户提问更精准地匹配数据库中的值
原始数据加工
For 表格数据 &数据库数据
物理表名称(原始表名)尽可能使用表意的英文+下划线(如purchase,sales,stock),避免使用简写、中文、拼音、特殊符号等
物理字段名称(字段原名称)类似物理表名,尽可能使用表意的英文名+下划线(如birth_date, sale_amount, sale_price)
字段类型与数据本身类型尽可能保持一致,如数值定义为字符串类型可能会导致生成的SQL无法执行
减少脏数据,如特殊符号、空值,非一致类型等;
对于枚举值,避免使用特殊的数字或编码,尽可能直接使用表意的中文,例如审批单状态有:审批中,已完成,已驳回等
不同表中代表同一含义的字段,尽可能使用统一的值格式,比如日期,避免一部分精确到日,一部分精确到秒
预加工复杂口径的字段,降低模型推理的难度,如涉及到总价= 单价 * 数量,如果直接有总价字段更明确;
减少有歧义的字段或值,如枚举项的多值问题
For 表格数据
Excel文件默认第一行为表头,表头要见名知意,表头长度为30个字符,不能为数字开头,尽量不使用特殊符号(注:当表头为空时,当前列所有数据都会被丢失);
Excel文件默认从第二行往下为表数据,每一列表数据的类型建议一致,如表头为【价格】数据列,建议都是数值型,不要出现字符串,否则当前类会被判断为字符串(注:当表数据为空时,当前数据被替换为NULL);
Excel文件数据类型为日期型时,建议采用Excel提供的标准日期类型,如2024-07-01、20240701;减少特殊日期类型的使用,如7.1.2024、0701-2024;
Excel文件优先选择XLSX格式,解析兼容性更好;针对xls格式的文件,EXCEL编辑器版本不低于2007;
Excel文件避免使用「合并单元格」、「公式计算」、「升序降序」等功能
能力边界
选择多个表后,支持对每个表进行智能分析,暂不支持多表之间的交叉分析。
若要追求高准确度,建议单次开启一个数据表进行分析。
针对多表分析的场景,可以提前基于数据工厂能力把多个表加工成一张大宽表进行问数。
所属商业化版本
免费版、高级版
常见问题
上传本地表格后,提示解析失败
答:请先按照模板格式上传,如果上传后仍解析失败,检查表格内容是否有合并单元格、数学公式、特殊字符,或者表头有纯数字,请避免这些情况的发生。
按照文档配置之后,外部系统为何无法正常访问数据库?
答:云数据库产商或者本地机房部署的数据库面向外部系统访问时,都有相关ip白名单设置,以阿里云RDS MYSQL为例:
确认预期云数据库 RDS,单击实例列表 > 白名单与安全组,进入白名单设置页面。
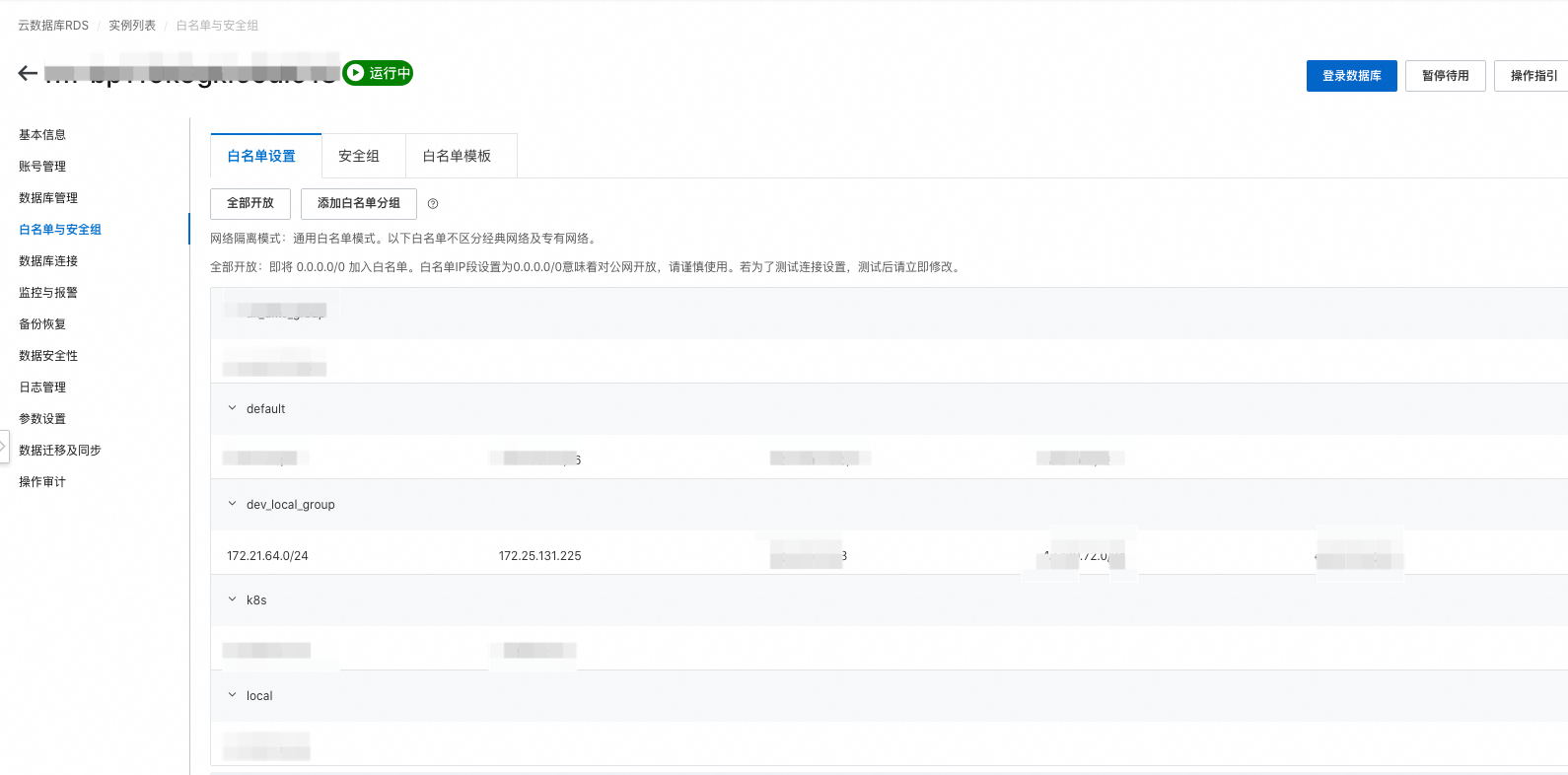
单击添加白名单分组,在白名单分组页面,填写对应白名单。
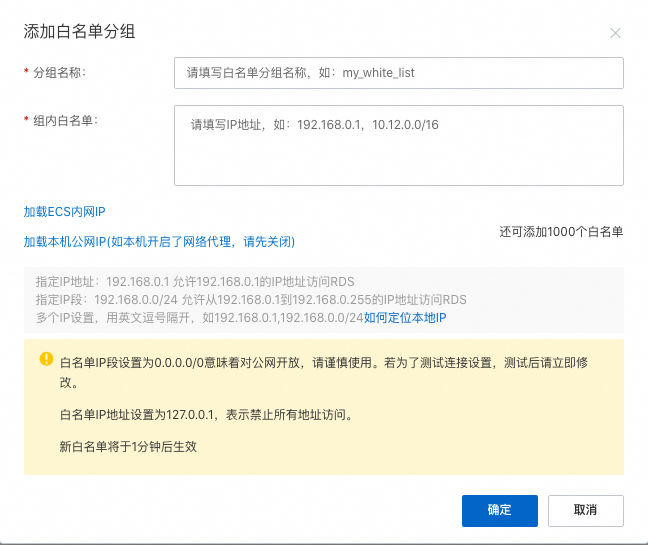
智能问数相关 IP 地址:106.11.0.0/16,203.119.128.0/17,59.82.0.0/16,140.205.0.0/16,100.68.0.0/16,100.66.0.0/16,111.225.0.0/16,111.63.0.0/16,116.132.0.0/16